

Val
-
Posts
1,115 -
Joined
Posts posted by Val
-
-
-
Par vislabāko vizītkarti kalpo 5-10 sekunžu ielādes laiks.
-
Ar javascriptu parādi/paslēp papildus input lauku, atkarībā no izvēlētās pilsētas.
-
-
Pēc jaunā gada nodoklis jau būs 3x128e, ja šogad neviens nenopirks. Bums.
Vai nu laist detaļās (diez kā ar pieprasījumu) vai norakstīt un pārdot kādam, lai pabraukājas, kur TA nav vajadzīga.
-
loģiski, ka var.
-
Jā, top...Tie CMS ir ļoti daudz un dažādi, šobrīd topā ir Wordpress.
cms, kas pietirš wp_options ar transient drazu, kas pēc noilguma neiztīrās, veic db kveriju, kas atgriež visus miljons useru ierakstus, pēc tam vēlreiz miljons pieprasījumu, lai iegūtu katra user_id (kas jau bija zināms) un meta_*, no kuriem 99.99% nemaz vēlāk netiek izmantoti lapas skatā. RAM taču ir lēts, pie*rāzt serveri un gala lietotājus.
-
Paldies, domāsim.
-
Pasūtītājs pats vēl nezin, cik daudz un dažādu lauku būs. Tāpēc tā...
-
Pacelšu mironi un paturpināšu tepat.
Taisu tā kā maziņu sludinājumu sadaļu. Kā jau augstāk minēts, tad auto sadaļai būs citi lauki, kaķu sadaļai motora tilpums nav vajadzīgs.
Sēžu un domāju tabulu struktūru, lai var definēt dažādus laukus dažādām sadaļām. Varbūt kāds no malas var pakomentēt vai ieteikt, ko taisīt savādāk.
Pamatlietas:
tabula classifieds: id title slug description date email value location blablabla tabula classifieds_categories id category slug parent_id hidden depth
Interesējošās lietas:
tabula classifieds_attributes (dažādi lauki, kurus var piekarināt pie konkrētām sludinājumu kategorijām) id category_id attribute_name attribute_type (select, input, radio, ...) attribute_label classifieds_values id classifieds_id attribute_id attribute_value
Nesmuki sanāk ar attribute_value, jo tur var būt gan skaitlis, gan teksts.
-
Iemet kādu skrīnšotu, kā tapa skices. Droši vien esi saglabājis. Būtu interesanti paskatīties, kā izveidojās tā lapa no nulles līdz tam, ko redzam šodien.
-
Paskaidro sīkāk.Būtu es šeit kaut ko metis ja nebūtu pats darijis? dohh!
-
Ko pats no tā visa darīji? Atkomentēji pārējo valodu izvēli?
-
Bērnudārzos sācies atvaļinājums?
-
Ja gribas čatot, tad tam ir domāti citi forumi.
-
301 Moved Permanently uz īsto linku.
-
Mēģini vēlreiz, meklējot cms*Interesanti ... uzmeklēju iekš php.lv frāzi "cms" - un saņēmu tukšu rezultātu. :)
-
csv failā vismaz ir redzamas diakritiskās rakstu zīmes?
-
Jā, pamēģināju, Mysql 5.0.92
Uz localhosta ar 5.5.36, ir lasāmāk.

Kopējais rezultāts diezgan līdzīgs. Kā arī šajā kverijā pat nav ietverta galarezultāta sortēšana pēc json datiem.


-
Sākuma dati:
27 ms uz lokālās kastes, 5.3 ms uz servera ar SQL_NO_CACHE

Starpsummas, grupējot pēc filtriem, kverijā mazāk jāsummē:
17 ms un 3.5 ms

Starpsummas, ar izmestiem filtriem, kverijā viss jau sasummēts:
11 ms un 2.5 ms

Var vienīgi vēl iekešot apmeklētājam redzamos datus uz noteiktu minūšu skaitu.
Īstenībā pat varētu atstāt pirmo versiju un pagaidām aizmirst par starpsummām, lai dati nedublētos. Pie tām atgriezties, ja sāks nejēgā slogot kasti.
Kā arī pārtaisīt šo tabulu uz
id, personas_id, filter1, filter2, stats1, stats2, stats3, stats4, ..., stats22, ... galigi negribas.



-
Es vēl cerēju, ka mysql ir kas labs izdomāts šādiem gadījumiem. Jāpārstāj sapņot.Starptabula ar sarēķinātiem varētu būt jēdzīgākais variants.
Daļēji jau patestēju vienkāršotā variantā.
Pa dienu jāuztaisa pilnais variants. Jautrība ar datu integritāti.
-
Jap, mana kļūda.Izņem to un jau jāuzlabojas izplildes plānam.
Tiku vaļā no viena temporary un filesort iekš testa kverija.


-
Labvakar,
izdomāju uzrakstīt, varbūt pametīsiet kādu ideju.
Doma tāda. Mysql tabula, kurā krīt iekšā statistikas dati. Value, filter kolonnas šajā gadījumā nav vajadzīgas, jo tiks izmantotas citur.
Tabulas struktūra un testa dati. Reālajā vidē tie būs daudz, daudz vairāk un sāksies problēmas ar summēšanu, tāpēc arī ir šis topiks.
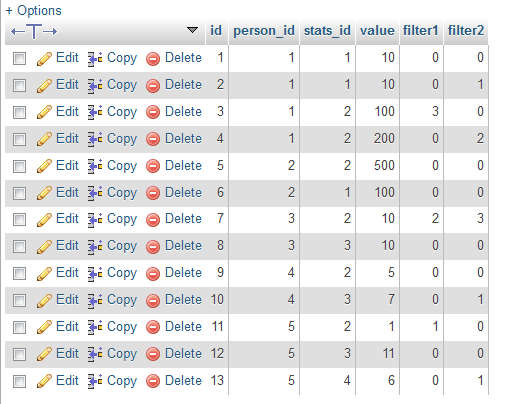
SQL zemāk spoiler tagos:
CREATE TABLE IF NOT EXISTS `testa_tabula` ( `id` int(5) unsigned NOT NULL AUTO_INCREMENT, `person_id` int(5) unsigned NOT NULL DEFAULT '0', `stats_id` int(5) unsigned NOT NULL DEFAULT '0', `value` int(5) unsigned NOT NULL DEFAULT '0', `filter1` tinyint(1) unsigned NOT NULL DEFAULT '0', `filter2` tinyint(1) unsigned NOT NULL DEFAULT '0', PRIMARY KEY (`id`), KEY `person_id` (`person_id`,`stats_id`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=14 ; INSERT INTO `testa_tabula` (`id`, `person_id`, `stats_id`, `value`, `filter1`, `filter2`) VALUES (1, 1, 1, 10, 0, 0), (2, 1, 1, 10, 0, 1), (3, 1, 2, 100, 3, 0), (4, 1, 2, 200, 0, 2), (5, 2, 2, 500, 0, 0), (6, 2, 1, 100, 0, 0), (7, 3, 2, 10, 2, 3), (8, 3, 3, 10, 0, 0), (9, 4, 2, 5, 0, 0), (10, 4, 3, 7, 0, 1), (11, 5, 2, 1, 1, 0), (12, 5, 3, 11, 0, 0), (13, 5, 4, 6, 0, 1);
Selects no testa tabulas.
SELECT person_id, coalesce(sum(case when stats_id = 1 then skaits end), 0) as s1, coalesce(sum(case when stats_id = 2 then skaits end), 0) as s2, coalesce(sum(case when stats_id = 3 then skaits end), 0) as s3, coalesce(sum(case when stats_id = 4 then skaits end), 0) as s4 FROM ( SELECT person_id, stats_id, COUNT(*) as skaits FROM testa_tabula GROUP BY person_id, stats_id ORDER BY skaits DESC ) AS X GROUP BY person_idRezultāts vizuāli: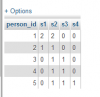
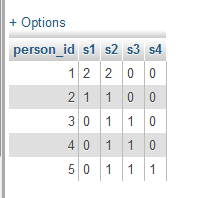
Meklēts tiek stats_id skaits sagrupēts pēc personas id.
Ar iespēju pēc tam sortēt pēc katras s1, s2, s3, s4... kolonnas, vienlaicīgi redzot pārējos datus.
Stats_id ar laiku palielināsies, bet ne bezgalīgi.
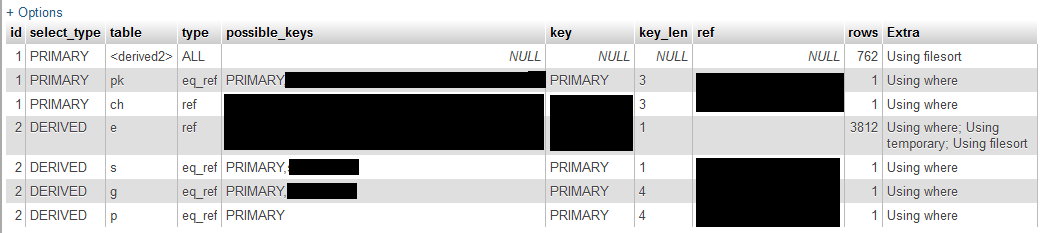
Kverija explain:


Uz puslīdz reāliem datiem, 90% kverija aizņem copying to tmp table, jo jāsasummē ir diezgan daudz, salīdzinot ar iegūstamo rezultātu.


Ieteikumi? Šo te kveriju ir iespējams uzlabot? Vai taisīt kaut kādu starptabulu ar jau sasummētiem datiem?
Joks tāds, ka esošo rezultātu kādreiz būs nepieciešams vēl arī filtrēt pēc citām kolonnām - filter1, filter2. Tāpēc vienīgais variants ir sasummēt grupējot pēc person_id, stats_id, filter1, filter2, kā rezultātā ierakstu skaits nemaz tik ļoti nesamazināsies.
//update:
Ar starptabulu sanāk daudz maz normāli, ja ignorē filter1 un filter2.
explain rezultāts: type=index, rows=81, extra=using where
-
wth varētu šamo pielodēt :mrgreen:

MySql vienlaicīgās konekcijas
in Instalācija un konfigurācija
Posted
iečeko mysqltuner.pl - kaut palīdzēs izrēķināt, cik katra konekcija apēd operatīvo atmiņu un vai teorētisko konekciju skaits maz ir iespējams ar esošo ram apjomu.